Выбор читателей



Популярные статьи
Где σ 2 j - внутригрупповая дисперсия j -й группы.
Для не сгруппированных данных
остаточная дисперсия
– мера точности аппроксимации, т.е. приближения линии регрессии к исходным данным:
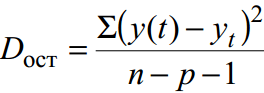
где y(t) – прогноз по уравнению тренда; y t – исходный ряд динамики; n – количество точек; p – число коэффициентов уравнения регрессии (количество объясняющих переменных).
В этом примере она называется несмещенная оценка дисперсии
.
Пример №1 . Распределение рабочих трех предприятий одного объединения по тарифным разрядам характеризуется следующими данными:
| Тарифный разряд рабочего | Численность рабочих на предприятии | ||
| предприятие 1 | предприятие 2 | предприятие 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Определить:
1. дисперсию по каждому предприятию (внутригрупповые дисперсии);
2. среднюю из внутригрупповых дисперсий;
3. межгрупповую дисперсию ;
4. общую дисперсию.
Решение.
Прежде чем приступить к решению задачи необходимо выяснить, какой признак является результативным, а какой – факторным. В рассматриваемом примере результативным признаком является «Тарифный разряд», а факторным признаком – «Номер (название) предприятия».
Тогда имеем три группы (предприятия), для которых необходимо рассчитать групповую среднюю и внутригрупповые дисперсии :

| Предприятие | Групповая средняя, | Внутригрупповая дисперсия, |
| 1 | 4 | 1,8 |

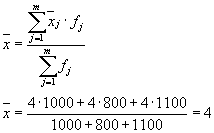

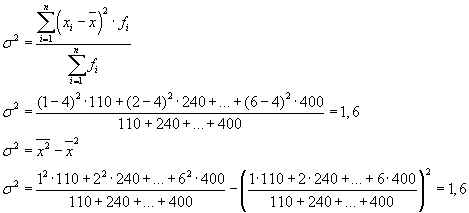
При решении практических задач часто приходится иметь дело с признаком, принимающим только два альтернативных значения. В этом случае говорят не о весе того или иного значения признака, а о его доле в совокупности. Если долю единиц совокупности, обладающих изучаемым признаком, обозначить через «р
», а не обладающих – через «q
», то дисперсию можно рассчитать по формуле:
s 2 = p×q
Пример №2 . По данным о выработке шести рабочих бригады определить межгрупповую дисперсию и оценить влияние рабочей смены на их производительность труда, если общая дисперсия равна 12,2 .
| № рабочего бригады | Выработка рабочего, шт. | |
| в I смену | во II смену | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Решение . Исходные данные
| X | f 1 | f 2 | f 3 | f 4 | f 5 | f 6 | Итого |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Итого | 31 | 33 | 37 | 37 | 40 | 38 |
| Номер группы | Групповая средняя | Внутригрупповая дисперсия |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
Пример №3 . На основе данных о средней заработной плате и квадратах отклонений от её величины по двум группам рабочих найти общую дисперсию, применив правило сложения дисперсий:
Решение:Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
Дисперсия в статистике определяется как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. Распространенный способ расчета квадратов отклонений вариантов от средней с их последующим усреднением.
![]()
В экономически-статистическом анализе вариацию признака принято оценивать чаще всего с помощью среднего квадратического отклонения, оно представляет собой корень квадратный из дисперсии.
 (3)
(3)
Характеризует абсолютную колеблемость значений варьирующего признака выражается в тех же единицах измерения, что и варианты. В статистике часто возникает необходимость сравнения вариации различных признаков. Для таких сравнений используется относительный показатель вариации, коэффициент вариации.
Свойства дисперсии:
1)если из всех вариант вычесть какое-либо число, то дисперсия от этого не изменится;
2) если все значения вариант разделить на какое-либо число b, то дисперсия уменьшится в b^2 раз, т.е.
3) если исчислить средний квадрат отклонений от какого-либо числа с неравного средней арифметической, то он будет больше дисперсии . При этом на вполне определенную величину на квадрат разности между средней величиной поc.
![]()
Дисперсию можно определить как разницу между средним квадратом и средней в квадрате.
Если статистическая совокупность разбита на группы или части по изучаемому признаку, то для такой совокупности могут быть исчислены следующие виды дисперсии: групповые (частные), средне групповые (частных), и межгрупповая.
Общая
дисперсия
–
отражает вариацию признака за счет всех
условий и причин, действующих в данной
статистической совокупности.
![]()
Групповая дисперсия - равна среднему квадрату отклонений отдельных значений признака внутри группы от средней арифметической этой группы, называемой групповой средней. При этом групповая средняя не совпадает с общей средней для всей совокупности.
![]()
Групповая дисперсия отражает вариацию признака только за счет условий и причин, действующих внутри группы.
Средняя групповых дисперсий - определяется как среднее взвешенное арифметическое из дисперсий групповых, причем весами являются объемы групп.
Межгрупповая дисперсия - равна среднему квадрату отклонений групповых средних от общей средней.
Межгрупповая дисперсия характеризует вариацию результативного признака за счет группировочного признака.
Между рассмотренными видами дисперсий существует определенное соотношение: общая дисперсия равна сумме средней групповой и межгрупповой дисперсии.
Это соотношение называется правилом сложения дисперсии.
Ряд в статистике - это цифровые данные, показывающие, изменение явления во времени или в пространстве и дающие возможность производить статистическое сравнение явлений как в процессе их развития во времени, так и по различным формам и видам процессов. Благодаря этому можно обнаружить взаимную зависимость явлений.
Процесс развития движения социальных явлений во времени в статистике принято называть динамикой. Для отображения динамики строят ряды динамики (хронологические, временные), которые представляют собой ряды изменяющихся во времени значений статистического показателя (например, число осуждённых за 10 лет), расположенных в хронологическом порядке. Их составными элементами являются цифровые значения данного показателя и периоды или моменты времени, к которым они относятся.
Важнейшая характеристика рядов динамики - их размер (объём, величина) того или иного явления, достигнутых в определённых период или к определённому моменту. Соответственно, величина членов ряда динамики - его уровень. Различают начальный, средний и конечный уровни динамического ряда. Начальный уровень показывает величину первого, конечный - величину последнего члена ряда. Средний уровень представляет собой среднюю хронологическую вариационного рада и исчисляется в зависимости от того, является ли динамический ряд интервальным или моментным.
Ещё одна важная характеристика динамического ряда - время, прошедшее от начального до конечного наблюдения, или число таких наблюдений.
Существуют различные виды рядов динамики, их можно классифицировать по следующим признакам.
1) В зависимости от способа выражения уровней ряды динамики подразделяются на ряды абсолютных и производных показателей (относительных и средних величин).
2) В зависимости от того, как выражают уровни ряда состояние явления на определённые моменты времени (на начало месяца, квартала, года и т.п.) или его величину за определённые интервалы времени (например, за сутки, месяц, год и т.п.), различают соответственно моментные и интервальные ряды динамики. Моментные ряды в аналитической работе правоохранительных органов используются сравнительно редко.
В теории статистики выделяют рады динамики и по ряду других классификационных признаков: в зависимости от расстояния между уровнями - с равностоящими уровнями и неравностоящими уровнями во времени; в зависимости от наличия основной тенденции изучаемого процесса - стационарные и не стационарные. При анализе динамических рядов исходят из следующего уровни ряда представляют в виде составляющих:
Y t = TP + Е (t)
где ТР – детерминированная составляющая определяющая общую тенденцию изменения во времени или тренд.
Е (t) – случайная компонента, вызывающая колеблимость уровней.
Теория вероятности - особый раздел математики, который изучают только студенты высших учебных заведений. Вы любите расчёты и формулы? Вас не пугают перспективы знакомства с нормальным распределением, энтропией ансамбля, математическим ожиданием и дисперсией дискретной случайной величины? Тогда этот предмет вам будет очень интересен. Давайте познакомимся с несколькими важнейшими базовыми понятиями этого раздела науки.
Даже если вы помните самые простые понятия теории вероятности, не пренебрегайте первыми абзацами статьи. Дело в том, что без четкого понимания основ вы не сможете работать с формулами, рассматриваемыми далее.
Итак, происходит некоторое случайное событие, некий эксперимент. В результате производимых действий мы можем получить несколько исходов - одни из них встречаются чаще, другие - реже. Вероятность события - это отношение количества реально полученных исходов одного типа к общему числу возможных. Только зная классическое определение данного понятия, вы сможете приступить к изучению математического ожидания и дисперсии непрерывных случайных величин.
Ещё в школе на уроках математики вы начинали работать со средним арифметическим. Это понятие широко используется в теории вероятности, и потому его нельзя обойти стороной. Главным для нас на данный момент является то, что мы столкнемся с ним в формулах математического ожидания и дисперсии случайной величины.

Мы имеем последовательность чисел и хотим найти среднее арифметическое. Всё, что от нас требуется - просуммировать всё имеющееся и разделить на количество элементов в последовательности. Пусть мы имеем числа от 1 до 9. Сумма элементов будет равна 45, и это значение мы разделим на 9. Ответ: - 5.
Говоря научным языком, дисперсия - это средний квадрат отклонений полученных значений признака от среднего арифметического. Обозначается одна заглавной латинской буквой D. Что нужно, чтобы её рассчитать? Для каждого элемента последовательности посчитаем разность между имеющимся числом и средним арифметическим и возведем в квадрат. Значений получится ровно столько, сколько может быть исходов у рассматриваемого нами события. Далее мы суммируем всё полученное и делим на количество элементов в последовательности. Если у нас возможны пять исходов, то делим на пять.

У дисперсии есть и свойства, которые нужно запомнить, чтобы применять при решении задач. Например, при увеличении случайной величины в X раз, дисперсия увеличивается в X в квадрате раз (т. е. X*X). Она никогда не бывает меньше нуля и не зависит от сдвига значений на равное значение в большую или меньшую сторону. Кроме того, для независимых испытаний дисперсия суммы равна сумме дисперсий.
Теперь нам обязательно нужно рассмотреть примеры дисперсии дискретной случайной величины и математического ожидания.
Предположим, что мы провели 21 эксперимент и получили 7 различных исходов. Каждый из них мы наблюдали, соответственно, 1,2,2,3,4,4 и 5 раз. Чему будет равна дисперсия?
Сначала посчитаем среднее арифметическое: сумма элементов, разумеется, равна 21. Делим её на 7, получая 3. Теперь из каждого числа исходной последовательности вычтем 3, каждое значение возведем в квадрат, а результаты сложим вместе. Получится 12. Теперь нам остается разделить число на количество элементов, и, казалось бы, всё. Но есть загвоздка! Давайте её обсудим.
Оказывается, при расчёте дисперсии в знаменателе может стоять одно из двух чисел: либо N, либо N-1. Здесь N - это число проведенных экспериментов или число элементов в последовательности (что, по сути, одно и то же). От чего это зависит?

Если количество испытаний измеряется сотнями, то мы должны ставить в знаменатель N. Если единицами, то N-1. Границу ученые решили провести достаточно символически: на сегодняшний день она проходит по цифре 30. Если экспериментов мы провели менее 30, то делить сумму будем на N-1, а если более - то на N.
Давайте вернемся к нашему примеру решения задачи на дисперсию и математическое ожидание. Мы получили промежуточное число 12, которое нужно было разделить на N или N-1. Поскольку экспериментов мы провели 21, что меньше 30, выберем второй вариант. Итак, ответ: дисперсия равна 12 / 2 = 2.
Перейдем ко второму понятию, которое мы обязательно должны рассмотреть данной статье. Математическое ожидание - это результат сложения всех возможных исходов, помноженных на соответствующие вероятности. Важно понимать, что полученное значение, как и результат расчёта дисперсии, получается всего один раз для целой задачи, сколько бы исходов в ней не рассматривалось.

Формула математического ожидания достаточно проста: берем исход, умножаем на его вероятность, прибавляем то же самое для второго, третьего результата и т. д. Всё, связанное с этим понятием, рассчитывается несложно. Например, сумма матожиданий равна матожиданию суммы. Для произведения актуально то же самое. Такие простые операции позволяет с собой выполнять далеко не каждая величина в теории вероятности. Давайте возьмем задачу и посчитаем значение сразу двух изученных нами понятий. Кроме того, мы отвлекались на теорию - пришло время попрактиковаться.
Мы провели 50 испытаний и получили 10 видов исходов - цифры от 0 до 9 - появляющихся в различном процентном отношении. Это, соответственно: 2%, 10%, 4%, 14%, 2%,18%, 6%, 16%, 10%, 18%. Напомним, что для получения вероятностей требуется разделить значения в процентах на 100. Таким образом, получим 0,02; 0,1 и т.д. Представим для дисперсии случайной величины и математического ожидания пример решения задачи.
Среднее арифметическое рассчитаем по формуле, которую помним с младшей школы: 50/10 = 5.
Теперь переведем вероятности в количество исходов «в штуках», чтобы было удобнее считать. Получим 1, 5, 2, 7, 1, 9, 3, 8, 5 и 9. Из каждого полученного значения вычтем среднее арифметическое, после чего каждый из полученных результатов возведем в квадрат. Посмотрите, как это сделать, на примере первого элемента: 1 - 5 = (-4). Далее: (-4) * (-4) = 16. Для остальных значений проделайте эти операции самостоятельно. Если вы всё сделали правильно, то после сложения всех вы получите 90.

Продолжим расчёт дисперсии и математического ожидания, разделив 90 на N. Почему мы выбираем N, а не N-1? Правильно, потому что количество проведенных экспериментов превышает 30. Итак: 90/10 = 9. Дисперсию мы получили. Если у вас вышло другое число, не отчаивайтесь. Скорее всего, вы допустили банальную ошибку при расчётах. Перепроверьте написанное, и наверняка всё встанет на свои места.
Наконец, вспомним формулу математического ожидания. Не будем приводить всех расчётов, напишем лишь ответ, с которым вы сможете свериться, закончив все требуемые процедуры. Матожидание будет равно 5,48. Напомним лишь, как осуществлять операции, на примере первых элементов: 0*0,02 + 1*0,1… и так далее. Как видите, мы просто умножаем значение исхода на его вероятность.
Ещё одно понятие, тесно связанное с дисперсией и математическим ожиданием - среднее квадратичное отклонение. Обозначается оно либо латинскими буквами sd, либо греческой строчной «сигмой». Данное понятие показывает, насколько в среднем отклоняются значения от центрального признака. Чтобы найти её значение, требуется рассчитать квадратный корень из дисперсии.

Если вы построите график нормального распределения и захотите увидеть непосредственно на нём квадратичного отклонения, это можно сделать в несколько этапов. Возьмите половину изображения слева или справа от моды (центрального значения), проведите перпендикуляр к горизонтальной оси так, чтобы площади получившихся фигур были равны. Величина отрезка между серединой распределения и получившейся проекцией на горизонтальную ось и будет представлять собой среднее квадратичное отклонение.
Как видно из описаний формул и представленных примеров, расчеты дисперсии и математического ожидания - не самая простая процедура с арифметической точки зрения. Чтобы не тратить время, имеет смысл воспользоваться программой, используемой в высших учебных заведениях - она называется «R». В ней есть функции, позволяющие рассчитывать значения для многих понятий из статистики и теории вероятности.
Например, вы задаете вектор значений. Делается это следующим образом: vector <-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
Дисперсия и математическое ожидание - это без которых сложно в дальнейшем что-либо рассчитать. В основном курсе лекций в вузах они рассматриваются уже в первые месяцы изучения предмета. Именно из-за непонимания этих простейших понятий и неумения их рассчитать многие студенты сразу начинают отставать по программе и позже получают плохие отметки по результатам сессии, что лишает их стипендии.
Потренируйтесь хотя бы одну неделю по полчаса в день, решая задания, схожие с представленными в данной статье. Тогда на любой контрольной по теории вероятности вы справитесь с примерами без посторонних подсказок и шпаргалок.
Виды дисперсий:
Общая дисперсия характеризует вариацию признака всей совокупности под влиянием всех тех факторов, которые обусловили данную вариацию. Эта величина определяется по формуле
где - общая средняя арифметическая всей исследуемой совокупности.
Средняя внутригрупповая дисперсия свидетельствует о случайной вариации, которая может возникнуть под влиянием каких-либо неучтенных факторов и которая не зависит от признака-фактора, положенного в основу группировки. Данная дисперсия рассчитывается следующим образом: сначала рассчитываются дисперсии по отдельным группам (), затем рассчитывается средняя внутригрупповая дисперсия:
 где
n i -
число единиц в группе
где
n i -
число единиц в группе
Межгрупповая дисперсия (дисперсия групповых средних) характеризует систематическую вариацию, т.е. различия в величине исследуемого признака, возникающие под влиянием признака-фактора, который положен в основу группировки.

где - средняя величина по отдельной группе.
Все три вида дисперсии связаны между собой: общая дисперсия равна сумме средней внутригрупповой дисперсии и межгрупповой дисперсии:
![]()
Свойства:
|
Коэффициент осцилляции |
|
|
Относительное линейное отклонение |
|
|
Коэффициент вариации |
|
Коэф. Осц. о тражает относительную колеблемость крайних значений признака вокруг средней. Отн. лин. откл . характеризует долю усредненного значения признака абсолютных отклонений от средней величины. Коэф. Вариации является наиболее распространенным показателем колеблемости, используемым для оценки типичности средних величин.
В статистике совокупности, имеющие коэффициент вариации больше 30–35 %, принято считать неоднородными.
Закономерность рядов распределения. Моменты распределения. Показатели формы распределения
В вариационных рядах существует связь между частотами и значениями варьирующего признака: с увеличением признака величина частоты сначала возрастает до определённой границы, а потом уменьшается. Такие изменения называются закономерностями распределения.
Форму распределения изучают с помощью показателей асимметрии и эксцесса. При исчислении указанных показателей используют моменты распределения.
Моментом k-го порядка называют среднюю из k-х степеней отклонений вариантов значений признака от некоторой постоянной величины. Порядок момента определяется величиной k. При анализе вариационных рядов ограничиваются расчетом моментов первых четырех порядков. При исчислении моментов в качестве весов могут быть использованы частоты или частости. В зависимости от выбора постоянной величины различают начальные, условные и центральные моменты.
Показатели формы распределения:
Асимметрия (As) показатель характеризующий степень асимметричности распределения.

Следовательно,
при (левосторонней) отрицательной
асимметрии  .
При (правосторонней) положительной
асимметрии
.
При (правосторонней) положительной
асимметрии .
.
Для расчета асимметрии можно использовать центральные моменты. Тогда:
 ,
,
где μ 3 – центральный момент третьего порядка.
- эксцесс (Е к ) характеризует крутизну графика функции в сравнении с с нормальным распределением при той же силе вариации:
 ,
,
где μ 4 – центральный момент 4-ого порядка.
Закон нормального распределения
Для нормального распределения (распределения Гаусса) функция распределения имеет следующий вид:


Матожидание- стандартное отклонение
Нормальное распределение симметрично и для него характерно следующее соотношение: Хср=Ме=Мо
Эксцесс нормального распределения равен 3, а коэффициент асимметрии 0.
Кривая нормального распределения представляет собой полигон(симметричная колокобразная прямая)
Виды дисперсий. Правило сложения дисперсий. Сущность эмпирического коэффициента детерминации.
Если исходная совокупность разделена на группы по какому-то существенному признаку, то вычисляют следующие виды дисперсий:
Общая дисперсия исходной совокупности:
где - общая средняя величина исходной совокупности;f– частоты исходной совокупности. Общая дисперсия характеризует отклонение индивидуальных значений признака от общей средней величины исходной совокупности.
Внутригрупповые дисперсии:
где j- номер группы;- средняя величина в каждойj-ой группе;- частотыj-ой группы. Внутригрупповые дисперсии характеризуют отклонение индивидуального значения признака в каждой группе от групповой средней величины. Из всех внутригрупповых дисперсий вычисляют среднюю по формуле:, где- численность единиц в каждойj-ой группе.
Межгрупповая дисперсия:
Межгрупповая дисперсия характеризует отклонение групповых средних величин от общей средней величины исходной совокупности.
Правило сложения дисперсий заключается в том, что общая дисперсия исходной совокупности должна быть равна сумме межгрупповой и средней из внутригрупповых дисперсий:
Эмпирический коэффициент детерминации показывает долю вариации изучаемого признака, обусловленную вариацией группировочного признака, и рассчитывается по формуле:
Способ отсчета от условного нуля (способ моментов) для расчета средней величины и дисперсии
Расчет дисперсии способом моментов основан на использовании формулы и 3 и 4 свойств дисперсии.
(3.Если все значения признака (варианты) увеличить (уменьшить) на какое-то постоянное число А, то дисперсия новой совокупности не изменится.
4.Если все значения признака (варианты) увеличить (умножить) в К раз, где К – постоянное число, то дисперсия новой совокупности увеличится (уменьшится) в К 2 раз.)
Получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:

А- условный ноль, равный варианте с максимальной частотой (середина интервала с максимальной частотой)
Расчет средней величины способом моментов также основан на использовании свойств средней.
![]()
Понятие о выборочном наблюдении. Этапы исследования экономических явлений выборочным методом
Выборочным называют наблюдение, при котором обследованию и изучению подвергаются не все единицы исходной совокупности, а только часть единиц, при этом результат обследования части совокупности распространяется на всю исходную совокупность. Совокупность, из которой производится отбор единиц для дальнейшего обследования и изучения называется генеральной и все показатели, характеризующие эту совокупность, называютсягенеральными .
Возможные пределы отклонений выборочной средней величины от генеральной средней величины называют ошибкой выборки .
Совокупность отобранных единиц называется выборочной и все показатели, характеризующие эту совокупность, называютсявыборочными .
Выборочное исследование включает следующие этапы:
Характеристика объекта исследования (массовые экономические явления). Если генеральная совокупность небольшая, то выборку проводить не рекомендуется, необходимо сплошное исследование;
Расчет объема выборки. Важно определить оптимальный объем, который позволит при наименьших затратах получить ошибку выборки в пределах допустимой;
Проведение отбора единиц наблюдения с учетом требований случайности, пропорциональности.
Доказательство репрезентативности, основанное на оценке ошибки выборки. Для случайной выборки ошибка рассчитывается с использованием формул. Для целевой выборки репрезентативность оценивается с помощью качественных методов (сравнения, эксперимента);
Анализ выборочной совокупности. Если сформированная выборка отвечает требованиям репрезентативности, то проводится ее анализ с использованием аналитических показателей (средних, относительных и проч.)
| Статьи по теме: | |
|
При каких условиях после месячных появляются кровянистые выделения причин возникновения нарушения под влиянием внешних факторов и гормонов
Порой бывает достаточно сложно отличить нормальные естественные причины... Успение праведной анны, матери пресвятой богородицы
Очень часто, обращаясь к иконам святой Анны или же с молитвой о помощи и... Человек умер. Что делать? Важнейшие православные традиции и обряды, связанные с похоронами. Православное учение о жизни после смерти Что такое смерть с точки зрения православия
Что такое смерть? «Верь, человек, тебя ожидает вечная смерть», - главный... | |




